In 60 minutes or less you can download a simplified topic modeling tool here https://code.google.com/p/topic-modeling-tool/ and you can grab some sample text corpora from Project Gutenberg (or just use these 20 James Fenimore Cooper novels or 14 Frank L. Baum Oz novels) and you too can explore topic modeling before our next class.
Category Archives: Resources
Hypergraphy as a Garden of Forking Paths
In zeroing in on a specific data set to begin with in my building-up-toward a more fully-conceived project for next Spring, I’ve found it necessary to first demarcate my chosen subject matter. To work backwards so to speak.
The prefix “hyper” refers to multiplicity, abundance, and heterogeneity. A hypertext is more than a written text, a hypermedium is more than a single medium. – Preface to HyperCities
Hypergraphy, sometimes called Hypergraphics or metaGraphics : a method of mapping and graphic creation used in the mid-20th century by various Surrealist movements. The approach shares some similarities with Asemic writing, a wordless open semantic form of writing which means literally “having no specific semantic content.” Some forms of Caligraphy (think stylized Japanese ink brush work) also share a similar function, whereby the non-specificity leaves space for the reader to fill in, interpret, and deduce meaning. The viewer is suspended in a state somewhere between reading and looking. Traditionally, true Asemic writing only takes place when the creator of the asemic work can not read their own writing.
Example work:

https://en.wikipedia.org/wiki/Hypergraphy#/media/File:GrammeS_-_Ultra_Lettrist_hypergraphics.jpg
Jorge Luis Borges was an Argentine short-story writer, essayist, poet, translator, and librarian. A key figure in the Spanish language literature movement, he is sometimes thought of as one of the founders of magical realism. He notably went blind in 1950 before his death. In his blindness, he continued to dictate new works (mostly poetry) and give lectures. Themes in his work include books, imaginary libraries, the art of memory, the search for wisdom, mythological and metaphorical labyrinths, dreams, as well as the concepts of time and eternity. One of his stories, the “Library of Babel”, centers around a library containing every possible 410-page text. Another “The Garden of Forking Paths” presents the idea of forking paths through networks of time, none of which is the same, all of which are equal. Borges goes back to, time and again, the recurring image of “a labyrinth that folds back upon itself in infinite regression” so we “become aware of all the possible choices we might make.”[88]
The forking paths have branches to represent these choices that ultimately lead to different endings.
Borges is also know for the philosophical term the “Borgesian Conundrum”. From wikipedia:
The philosophical term “Borgesian conundrum” is named after him and has been defined as the ontological question of “whether the writer writes the story, or it writes him.”[89] The original concept put forward by Borges is in Kafka and His Precursors—after reviewing works that were written before Kafka’s, Borges wrote:
If I am not mistaken, the heterogeneous pieces I have enumerated resemble Kafka; if I am not mistaken, not all of them resemble each other. The second fact is the more significant. In each of these texts we find Kafka’s idiosyncrasy to a greater or lesser degree, but if Kafka had never written a line, we would not perceive this quality; in other words, it would not exist. The poem “Fears and Scruples” by Browning foretells Kafka’s work, but our reading of Kafka perceptibly sharpens and deflects our reading of the poem. Browning did not read it as we do now. In the critics’ vocabulary, the word ‘precursor’ is indispensable, but it should be cleansed of all connotation of polemics or rivalry. The fact is that every writer creates his own precursors. His work modifies our conception of the past, as it will modify the future.”
I’m circling around 2 or 3 different project ideas:
- Close Reading/Qualitative Analysis: Hypertextualizd Borges poems/short stories with an emphasis on works created during his period of blindness, re-imagined as a garden of forking paths. Break down the works into levels of constituent parts. Create an engine to re-esemble them based on a methodological algorithm informed by his ideas surrounding non-linearity, and the morphology of his oeuvre.
1.5 *Potential Visualization Component: Hyperagraphy Engine (simulated blindness) that interacts with the hypertextualized artifacts from 1.0. - Distance Reading/Quantitative Analysis: Topics as “forms of discourse” in Borges and his precursors (Potential Candidates: Cervantes, Kafka, Schopenhauer, Quevedo, Gracian, Pascal, Coleridge, Poe.)
- …..(Running out of time, will continue this post tonight).
Taylor
A few resources from the recent NEH Project Director’s Meeting
I recently attend an NEH Project Director’s meeting in DC and wanted to share news of a few projects that I thought might interest the group:
Massmine.org
(in pre-release)
http://www.massmine.org/

“MassMine is a social media mining and archiving application that simplifies the process of collecting and managing large amounts of data across multiple sources. It is designed with the researcher in mind, providing a flexible framework for tackling individualized research needs. MassMine is designed to run both on personal computers and dedicated servers/clusters. MassMine handles credential authorizations, data acquisition & archiving, as well as customized data export and analysis.”
Poemage: A Visualization Tool in Support of Close Reading
http://www.sci.utah.edu/~nmccurdy/Poemage/
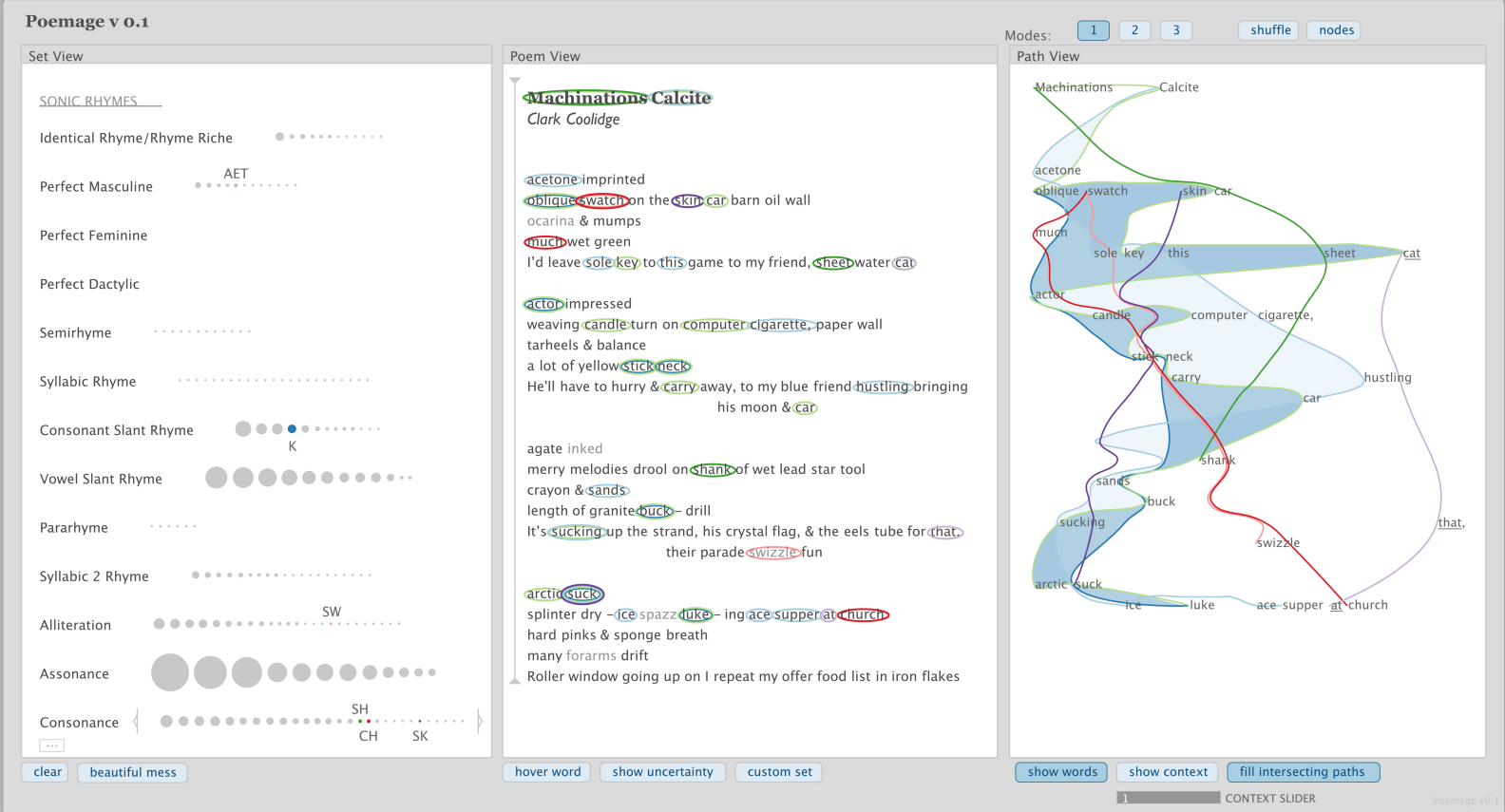
“Poemage is a visualization system for exploring the sonic topology of a poem. We define sonic topology as the complex structures formed via the interaction of sonic patterns — words connected through some sonic or linguistic resemblance — across the space of the poem. Poemage was developed at the University of Utah as part of an ongoing, highly exploratory collaboration between data visualization experts and poets/poetry scholars. Additional details are provided in the companion paper [to appear in IEEE Transactions on Visualization and Computer Graphics].”
New DHDebates CFP is Up
We’ve been looking at various barometers of the field in recent weeks (conferences, blog postings, tweets, etc.), so I wanted to mention that Lauren Klein and I posted the Call for Papers for the 2017 edition of Debates in the Digital Humanities today. Some of you might be interested in looking through it to get a sense of the questions we’re asking and how they map to current concerns in the field.

Difficult Thinking, Cultural Criticism, and Niceness in DH
Suggested Reading and a Summer Institute
In “Difficult Thinking about the Digital Humanities” from last week’s reading, Mark Sample discusses critical thinking in comparison to facile thinking and how accounts of facile thinking “eliminate complexity by leaving out history, ignoring examples, and – in extreme examples – insisting that any other discourse about the digital humanities is invalid because it fails to take into consideration that particular account’s perspective.” He references Alan Liu’s call for more cultural criticism in DH as an example of similar initiatives. Liu’s call for more cultural criticism in DH seems more of a side note in our recent readings, including this week’s “Digital Humanities and the ‘Ugly Stepchildren’ of American Higher Education” by Luke Waltzer. I would’ve liked to read more on the subject of DH criticism outside of the methodology conversation, as described below in articles by Alan Liu and Adeline Koh:
- Alan Liu, “Where is Cultural Criticism in the Digital Humanities”
- Adeline Koh, “A Letter to the Humanities: DH Will Not Save You”
Rough stuff.
I also have below another Koh article that could be read in conjunction with Tom Scheinfeldt’s “Why Digital Humanities Is ‘Nice’” and Lisa Spiro’s “‘This Is Why We Fight’: Defining the Values of the Digital Humanities.” Koh focuses her argument on the neutrality of “niceness” and the exclusionary nature of more “hack” than “yack,” articulating my personal anxieties regarding the social and technical requirements of DH.
On additions to the syllabus for today’s DH Pedagogy topic, I suggest taking a look at the Humanities Intensive Learning & Teaching Institute, or HILT2015, an annual summer institute that provided workshops on digital pedagogy and criticism with courses such as “Getting Started with Data, Tools, and Platforms” and “De/Post/Colonial Digital Humanities.”
Disciplinarity debates – suggested readings
The media analysis project David proposed seems extremely timely. The top hits in a Google search on science and humanities brought up article after article about the crisis in the humanities, the perceived or false threat to the humanities by scientific and quantitative approaches, the scientism and the humanities (cf the very public 2013 argument between Leon Wieseltier and Steven Pinker in The New Republic – http://www.newrepublic.com/article/114127/science-not-enemy-humanities and http://www.newrepublic.com/article/114172/leon-wieseltier-scientism-and-humanities ), etc. It all gets so old after while! And it’s not a new set of concerns.
But I came across a NEH grant proposal narrative / position paper prepared by SUNY Binghamton in 2008 for a project that sought to address the Science v. Humanities smackdown before it ever reached its current frenzy. They begin with “C.P. Snow’s (1959) description of the humanities and sciences as ‘The Two Cultures.’” And the project was aimed at breaking down this dichotomy where it matters most, at the level of the classroom (rather than continue the argument at the disciplinary level, which doesn’t actually do anything but feed the fire). Some of the project description is understandably very specific in terms of activities, but it also addresses larger theoretical questions, such as how humanities research and scientific research can complement or enhance each other in a given subject, and how a holistic investigation and interpretation of evolution, for example, could encompass different approaches to the material that are both equally valid and equally necessary: “Through evolutionary theory and its study of both ultimate explanations (such as biological fitness) and proximate explanations (such as the function and importance of the arts to human survival and development), we think that the 21st century will witness an integration of human-related subjects. Moreover, because of its emphasis on the crucial developmental functions of art, this integration can help restore the centrality of the perspectives and subjects currently associated with the humanities. ”
The project description also surveys the modern history of this disciplinary antipathy, which I think is very useful for background. Although it is not specifically a DH project, it addresses some fundamental assumptions and anxieties that contribute to current divisions and drive the debate in academia. And, as these ideas “trickle down” into the popular press, they generate both the less partisan articles like those David suggested, as well as those that politicize and perpetuate these divisions in (I think) unnecessary ways. The proposal is here: http://evolution.binghamton.edu/evos/wp-content/uploads/2009/08/Wilson-02.pdf
Ways that Humanists Think About Data – An alternative text for in-class discussion
Up to this point, I’ve enjoyed our in-class discussions. Typically, I leave with an unfocused, impending fatigue that transforms during my subway ride home into a grounded awareness of the gaps in my thinking about DH theory, what questions I have more generally about how DH fits into the larger context of humanistic inquiry in the academy, as well as a slightly more refined awareness of how I see myself finding my place in the field.
Last week I left, running through potential ideas for my data project, wishing I had articulated the desire for (in an effort to create a lexicon) a more specific discussion about terms related to actual DH projects. I found myself trying to anticipate the unique ways in which humanities scholars think about data. Data sets and maps generally, are obviously representations of a more complex, dynamic, ambiguous world. How have DH practitioners found inspiration in this reality, and what potential solutions and tools already exist? How can the gap between the “real” and the represented be used fruitfully? How can uninterpreted data result in new ways of seeing?
After reading Stephen’s Ramsay’s “Programming with Humanists: Reflections on Raising an Army of Hack-Scholars in the Digital Humanities” I found myself setting aside time to research what exactly went into “word frequency generators” and “poetry deformers”. He mentions a list of tools for analyzing text corpora: tf-dif analyzers, basic document classifiers, sentence complexity tools, etc, as well as natural language processing tools, as potential programs that could be built during a computer science introduction focusing on humanities computing. Hashing out a basic explanation about what these programs do, and potentially a bit about how they do it, would contribute an additional, fruitful dimension to our praxis seminar discussions. I have a sense that learning more about what tools exist would go a long way in helping me zero in on a meaningful dataset.
**As an aside, as I bet not everyone will have had a chance to read this particular article, I should mention that I also really appreciated Ramsay’s extensive list of supplemental reading materials, some of which I have read (The Question Concerning Technology Martin Heiddeger, and others that I would love to spend some time with like NOW, The Work of Art in the Age of Mechanical Reproduction for example.)**
During my research I came across an excellent blog post by Miriam Posner titled Humanities Data: A Necessary Contradiction in which she engages some of the questions that are preoccupying me in lieu of having to choose my dataset. In her blog post she provides a transcript of a talk she gave at the Harvard Purdue data symposium this past summer. Her talk focused on the unique ways that humanists think about data vs say a scientist or a social scientist, and the implications of these differences for librarianship and data curation. I’ll list a couple prescient quotes and a link to her post. If you have some time, check it out!
“It requires some real soul-searching about what we think data actually is and its relationship to reality itself; where is it completely inadequate, and what about the world can be broken into pieces and turned into structured data? I think that’s why digital humanities is so challenging and fun, because you’re always holding in your head this tension between the power of computation and the inadequacy of data to truly represent reality.”
Or
“So it’s quantitative evidence that seems to show something, but it’s the scholar’s knowledge of the surrounding debates and historiography that give this data any meaning. It requires a lot of interpretive work.”
Cheers,
Taylor
Data Project Posts from the 2014 Praxis Class
Hi All,
If you would like to see posts that students in last year’s Praxis course made in connection with the dataset assignment, please look at the posts tagged “dataset” and “data project.”
If you’d like to look through the blog as a whole (used in both the Fall and Spring semesters), please visit http://cuny.is/dhpraxis14. And here is the 2013-2014 class archive, which included a great series of lectures. Perhaps we can talk next week about the different shapes this class has taken over the three-year period of its existence. In the first year, we brought in many guest speakers, but in response to student feedback, we have curtailed that over the past two years.
Great resource for digital tools
Here is a great resource, The Programming Historian
@AcademicsSay
We’ll talk about scholarly communication all semester, and on Thursday specifically about Kirschenbaum’s argument that DH is in part “a populist term, self-identified and self-perpetuating through the algorithmic structures of contemporary social media,” but here’s a recent example of how it works in practice: the author of the popular parody Twitter account “Shit Academics Say” (@AcademicsSay) recently outed himself and described the reasons why he created the account. He even shares his graduate school syllabus on “Digital and Social Media in Higher Education.”