My data set project turned out a lot different from what I envisioned. I found my data from the Integrated Postsecondary Education Data System (IPEDS). They have a Trend Generator System, which easily helps you generate data, and you can see how this data changed over time. So, I looked at the percentage of bachelor students who graduated within 150% normal time (6 years) at 4 year postsecondary institutions in cohort year 2007. I broke the data down by state and race/ethnicity.
I wanted to do a mapping of this data to help us visualize these numbers. After seeing what UC Berkley did with their Urban Displacement project, my goal was to emulate something similar and continue to work on it for the final project. After using CartoDB, it was really not giving me what I wanted. I couldn’t separate the cluster of plotting points. Each layer also acted as an individual layer that didn’t add up with previous data/layers I mapped. For instance, here’s what I got when I added two other layers to the map:

The black and red bubbles aren’t really points…. Then I tried to create another map, a choropleth map. This map shows the different percentage of Asians who graduated at normal time. If you click on each state, a pop-up shows the graduation rate for other race/ethnic groups.
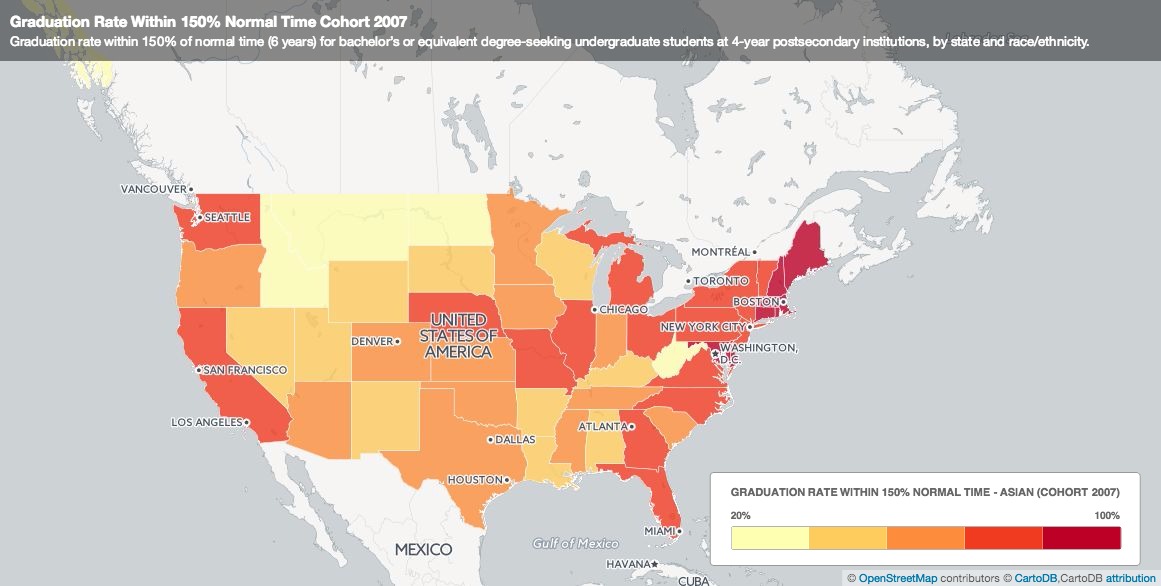
This wasn’t what I wanted at first, but it was what I got. Then I was thinking, is this enough? Do I need an actual map in my visualization? How does this map help me compare my data? I decided to turn to Plotly just to do some visualization with charts. Here was what I came up with:
A three y-axes graph:

A scatter plot:
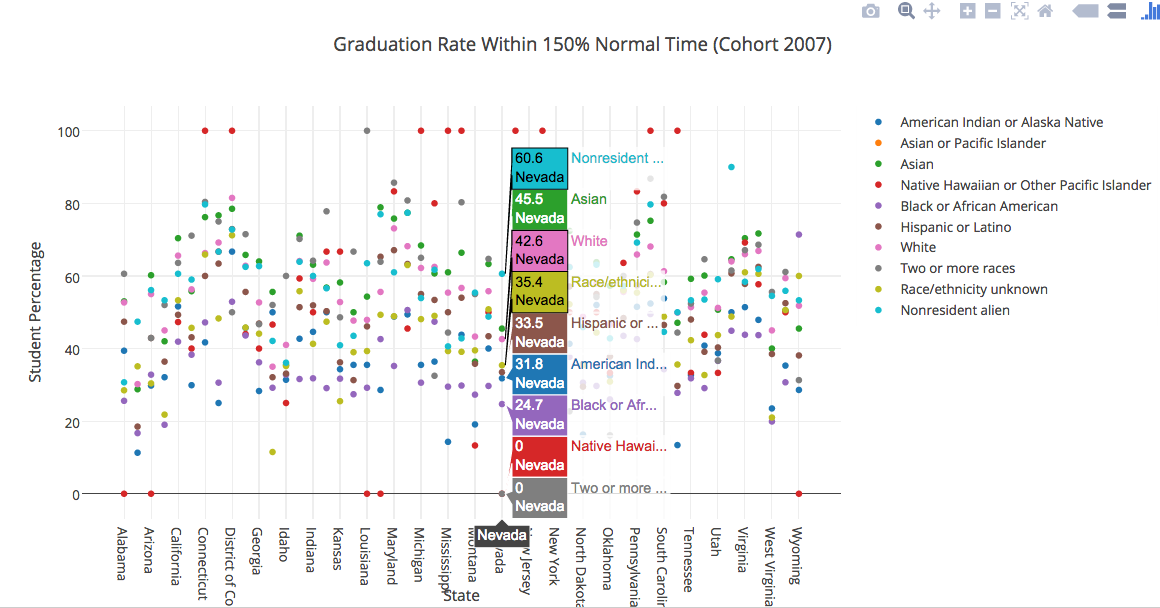
Even with these two charts, there’s still limitations to visually seeing the data. I’m hoping that in the next couple of weeks, I’ll either find a tool that matches with what I want or I’ll try to manipulate my data more and see what I get.